Section 8 Are positions sampled serially?
Brains have a massively parallel architecture. Yet as we have seen, tracking performance drops steeply with target load, indicating that tracking is highly capacity-limited. Even with a capacity limitation, however, processing might remain completely parallel. In that scenario, lots of stimuli could still be simultaneously processed, but with a large time or accuracy cost. However, in worlds like this one, animals have priorities and time is at a premium. To out-compete others, one needs to distinguish rapidly between friend and foe. As a practical matter, then, limited-capacity processes are unlikely to be spread thinly across dozens of stimuli. Instead, they are likely to be allocated in serial, processing small subsets of targeted stimuli, one small group after another. These subsets may consist of just one stimulus, with processing happening one-by-one.
Whether the processes that underlie MOT involve a serial component has been one of the chief concerns of researchers since the very first paper on the topic by Z. W. Pylyshyn and Storm (1988). Thiss has been a major preoccupation of the field more generally too. Many researchers have been influenced by Anne Treisman’s theory that certain forms of feature binding and other judgments require a serial one-by-one process. Still, more than forty years after Treisman sparked a large literature on the topic, whether various mental processes occur one-by-one or not remains unresolved - although my money is on one-by-one for certain forms of feature binding, and possibly other processes.
8.1 Spatial relationships - a case study of serial processing
The evidence is fairly strong that at least a few forms of binding, in particular judgments of arbitrary spatial relationships, involve a one-by-one process. The evidence comes from at least five different approaches. In their redundant-target paradigm, David Gilden and colleagues improved on the inferential power of the visual search approach of Treisman (Thornton and Gilden 2007). The results indicated that discriminating many spatial relations, such as distinguishing betwee the two symbols below , requires a serial process (Gilden, Thornton, and Marusich 2010).

Figure 8.1: The evidence indicates that in visual search experiments with one of these symbols as the target and the other as the distractor, a serial process is required.
Daniel Linares, Maryam Vaziri-Pashkam, and I presented colored discs rapidly moving in a circular trajectory about the fixation point. When the discs moved at speeds that exceeded the participants’ tracking limit, participants were unable to report which discs were adjacent to each other, even when they were presented for multiple seconds. This suggested that attention, in particular that deployed when tracking, is necessary for judging spatial relationships.
Figure 8.2: When the discs in this display rotated faster than about 1.4 rps (approximately the 1-target tracking limit with this display), participants were unable to judge whether two colors are adjacent to each other.
An additional result suggested that the spatial relationship is mediated by an attentional shift. When the discs were moving slow enough that participants could often do the task (like in the above movie) but sometimes made errors, the errors had a systematic pattern. The task was to report which disc was aligned with a target disc. Participants tended to err by reporting the trailing disc next to the target rather than the aligned disc, consistent with them making a time-consuming shift of attention from the target, which sometimes landed on the trailing disc because the aligned disc had moved on by the time the attention shift landed (Alex O. Holcombe, Linares, and Vaziri-Pashkam 2011). Based on EEG signals and also eye movement data when the eyes were not constrained, Steven L. Franconeri et al. (2012) found evidence for an attentional shift when judging the spatial relationship between static stimuli. In a dual-task design, Lee, Koch, and Braun (1999) showed that while several judgments could be made concurrently with an attention-demanding task at the fovea, judgments of the spatial relationship between two stimuli (whether a bisected disk had red on the left or on the right) could not. Finally, using a visual working memory paradigm to investigate the effect of set size, exposure duration, and simultaneous versus serial presentation, P. L. Smith et al. (2016) also found evidence consistent with a serial process involved in discrimination of spatial relations.
Because in any one paradigm, serial and parallel processes can yield similar or identical data, a number of experimental manipulations were needed to provide strong evidence of serial processing for spatial relationships. For example, while visual search results led Treisman to conclude that conjoining two spatially superposed features, such as red with leftward tilted, required a serial process of focused attention (Treisman and Gelade 1980), such results are explainable by limited-capacity parallel processing (Palmer 1995), and the redundant-target paradigm of Thornton and Gilden (2007) suggested that no serial process is involved.
8.2 A case for serial position sampling
Before I launch into a discussion of evidence consistent with serial sampling, please keep in mind that this evidence is also consistent with limited-capacity parallel, it’s just that such models may require some less-plausible assumptions, as we will discuss in the next section.
Like for other processes, for object tracking we should wait for strong evidence before concluding that tracking involves a serial one-by-one process. There are some difficulties involved in adapting the paradigms developed for judgments involving static stimuli, so the evidence needed cannot be obtained by applying the same techniques as were used for spatial relationship judgments.
Let’s clarify exactly what our interest is here. The front end of visual processing, from the retina to primary visual cortex, that registers the basic elements of color, form, and motion, clearly operates in massively parallel fashion. The question, then, is whether any process important for tracking is serial. By “any process,” I don’t mean processes during the response phase, such as clicking on the objects one think are targets, or the daydreaming that may occur while one is also doing the task. Instead, I’m referring to processes that are ordinarily necessary for tracking to be accomplished while the objects are moving.
While the nature of MOT closes off some methodological paradigms for investigating the serial/parallel issue, it does provide a new kind of evidence for serial processing. In particular, after a few assumptions are made, serial sampling makes a specific prediction for the temporal limits on tracking. What I’ll call the fundamental assumption is that after a moving target’s position is sampled, if its position is not re-sampled before another object comes close to the previously-sampled position, the target will be lost. This is a consequence of the visual system assuming that the objects nearest to the last-recorded positions of the targets are, in fact, the targets. Part of this assumption is that motion direction and speed are not used to predict where the target should be when the position-sampler switches back to a target. The evidence that supports this aspect of the assumption is discussed in section 6, but note that even if it is false, under some ways that it could be false, this would simply reduce the the size of the effects predicted by the serial account.
For circular trajectories such as those used by Alex O. Holcombe and Chen (2013), a consequence of the fundamental assumption is that the product of the speed (in revolutions per second) and number of objects determines how often sampling must be done to avoid losing a target. In an MOT trial with two targets, after one target is sampled, a one-by-one serial process would switch to the other target. If the distractor trailing the target arrives near the first target’s former location before the serial process switches back, then we can expect tracking to fail.
An increase in the number of targets proportionally reduces how often each individual target is sampled. As a result, the serial switching account predicts a linear relationship between the number of targets and the temporal limit on tracking. In Figure 8.3 below, predictions are plotted under two scenarios: if tracking samples position and switches to another object every 60 ms, and if tracking alternatively samples and switches every 90 ms.
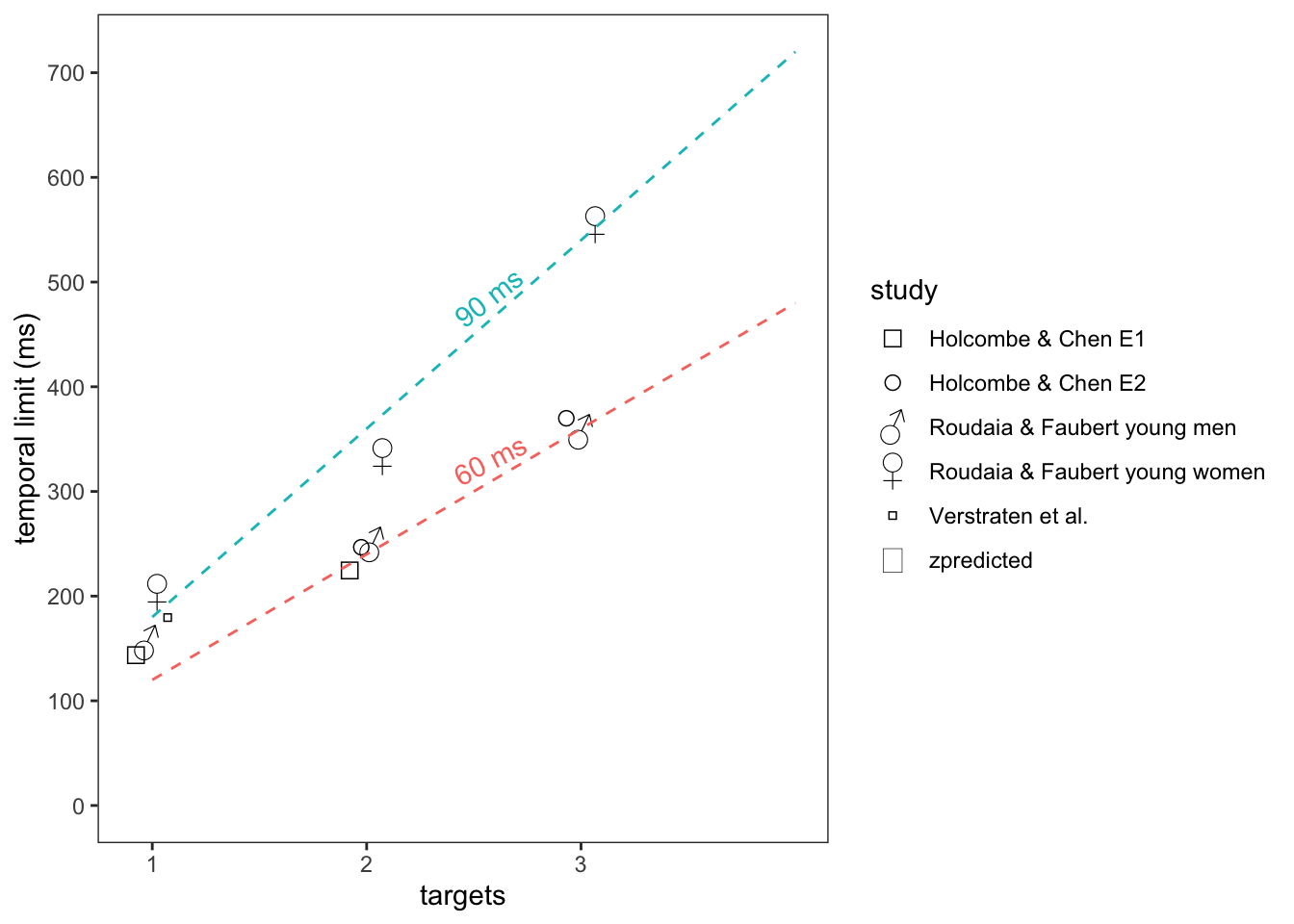
Figure 8.3: The predictions of 60 and 90 ms sampling time are plotted as dashed lines, together with data from Holcombe & Chen (2013) and Roudaia & Faubert (2017). The data symbols are horizontally offset to avoid overlap.
This prediction is based on an optimistic assumption of orderly sampling (the sampling process sampling first one target, then the second target, then the third target, and back to the first target, rather than sampling the second target or third target again); otherwise the predicted slope should be even steeper.
Because a particular sampling time specifies the temporal limits for all target sizes, no parameters needed to be fit to derive the predictions. That is, the dashed lines in Figure 8.3 are not best-fitting regression lines. Their slope and intercept are determined by the sampling time indicated. The lines fit the data fairly well. But how impressed should we be by this? Not very.
A first problem is that only three target loads were tested, so we should have little confidence that the relationship is truly linear in the way that the model predicts. A second problem is that in principle, the temporal limit for covertly tracking a single target could be set by a different process than the serial switching hypothesized to set the limit for two and three targets, because with a single target, there is no need to switch attention around. Suprisingly, however, evidence from other paradigms suggests that even when only a single static location is relevant for attention, performance oscillates over time, a pattern which has been dubbed the “blinking spotlight of attention” (VanRullen, Carlson, and Cavanagh 2007; Fiebelkorn, Saalmann, and Kastner 2013).
Thus, we should not really expect the temporal limit for one target to fall on the same line as that for two and for three targets. Yet in the plotted data (Figure 8.3), it can be seen that the one-target limit may actually fall on the same line. It’s as if the sampling interval of attention for a single static location also sets the inter-object sampling interval. While the data are consistent with this, they support this proposition only weakly, because there is considerable statistical uncertainty associated with the data points.
The lower clusters of points on the graph represent the male and predominantly-male datasets. They imply temporal limits, when tracking one target, of between 140 and 200 ms. Recall that because the target must be sampled at twice the temporal limit to avoid confusion with the trailing distractor, one could infer sampling rates from this between 70 and 100 ms. This assumes near-perfect linking of a target’s last-sampled position with the nearest neighbor in the new sample, otherwise one should estimate a higher sampling rate. The example dashed lines represent the predictions if sampling occurred at 60 ms (red) and 90 ms (blue) and switching occurred systematically rather than visiting one target twice before sampling the third.
How do these numbers compare to sampling intervals inferred with other paradigms? Macdonald, Cavanagh, and Vanrullen (2013) studied the continuous wagon-wheel illusion, in which a rotating spoked circle is sometimes perceived to rotate backwards, for which a leading explanation is intermittent sampling (Alex O. Holcombe 2014). Asking participants to report reversals when they viewed multiple spoked circles, they inferred a sampling interval of 75 ms, which assumes, among other things, that perceived reverse motion is strongest when the wheel travels three-quarters of the inter-spoke angle between samples, yielding a one-quarter backwards rotation with each sample. Their 75 ms figure is similar to what we inferred from tracking. However, Derek H. Arnold, Pearce, and Marinovic (2014) found that the peak frequency for perception of illusory backwards rotation differed for equiluminant motion (5 Hz) and luminance-defined motion (10 Hz in their test), suggesting that results from such experiments cannot be interpreted as providing a constant simple sampling rate for high-level vision.
Studies that use other behavioral paradigms in an attempt to investigate visual sampling suggest sampling intervals longer than 100 ms: 140 ms (Re et al. 2019), 142 ms (VanRullen, Carlson, and Cavanagh 2007), 130 ms (Fiebelkorn, Saalmann, and Kastner 2013), and 140 ms (Dugué et al. 2015), although the statistics used in some of these studies may have led to spurious findings (Brookshire 2021). A visual search study that recorded from neurons in monkeys suggested a 44 ms sampling interval (Buschman and Miller 2009). These other studies all used stationary objects or multiple locations that the participant was told to monitor, which conceivably could explain the slower sampling intervals found in some, but there also remains ample reason otherwise for uncertainty.
Despite the sizable and growing neurophysiological and neuroimaging literature on oscillations and intermittent sampling, I have not found a study that tests whether the sampling operates independently in the two hemifields. This is unfortunate given that a hallmark of tracking is its hemifield independence, as reviewed in ??.
It might turn out that even after researchers regularly assess whether the sampling they are measuring is hemifield-independent, there will continue to be a large range of rates found. If so, perhaps different tasks result in different sampling rates, and the sampling process can occur more quickly for tracking as it requires sampling position only. Another possibility is that the assumptions underlying the calculations in behavioral studies such as object tracking are wrong. If, for example, motion direction is used to guide the next position sampled, tracking could succeed with a slower sampling interval more similar to those documented in most of the neural studies cited above (but see section 6).
A few studies, while finding evidence for oscillations in some conditions, do not find it to be tied to cued locations in the same way as other papers cited above suggest (Werf et al. 2021; Peters et al. 2020). The fact that psychology and neuroscience researchers admit to substantial rates of publication bias and p-hacking (Jennings and Van Horn 2012; John, Loewenstein, and Prelec 2012; Rabelo et al. 2020) raises the spectre of further, unpublished, evidence that is inconsistent with the prevailing narrative of regular oscillations that correspond to an attentional sampling rate.
In summary, despite a wealth of neuroscientific evidence that serial sampling occurs for attentional tasks, which might account nicely for the existence of a coarse temporal limit on tracking, and for its dramatic worsening with target load, more evidence would be needed for this to be strongly supported.
### Limited-capacity parallel processing and temporal limits
Conceivably, a parallel process of evidence accumulation with limited capacity could also produce a steep and linear worsening of temporal limit with target load. Under this account, when attention is split among multiple targets, this greatly slows the rate that of accumulation of evidence for some process that is critical to tracking. This process might be linking successive position samples. However, despite some diversity in the computational models that have been advanced so far, none show behavior like that.
What modellers have done is suggested that spatial (not temporal) noise rapidly worsens with number of targets (e.g. Srivastava and Vul 2016). This does not, however, predict the above data, instead it predicts that spatial limits (spatial interference) will worsen with number of targets, which seems to be a small or non-existent effect (see chapter 5). A focus on temporal factors in visual processing is much more common in other literatures, such as decision-making and categorization, where drift diffusion and other dynamical models are popular. The focus on time comes from the fact that many of those tasks have no spatial component to them and historically have used response time as the main dependent variable. I know of no work that has resulted in positing such a steep increase in time when an additional target is added, but I admit that I am quite ignorant of this literature.
## Evidence for parallel processing
Piers Howe and his colleagues investigated a different aspect of tracking (not temporal limits) and found some evidence against involvement of a serial process in tracking (P. D. L. Howe, Cohen, and Horowitz 2010). Specifically, the simultaneous-sequential presentation technique developed by Shiffrin and Gardner (1972) was appplied to MOT. The technique was originally developed to investigate whether several stationary stimuli could be processed in parallel, in service of some visual judgment, without being affected by any capacity limit. The stimuli are presented either all at once (simultaneously) or in succession (sequentially) during a trial, half the stimuli presented in the first interval, and the other half in the second interval. To equate the total amount of time each stimulus is presented in the simultaneous and successive conditions, a trial in the simultaneous condition is only half as long as that of the successive condition. The technique has been applied extensively to the detection of a particular alphanumeric character among other alphanumeric characters, and researchers have found that processing in the simultaneous condition is equal to or better than the sequential condition (Shiffrin and Gardner 1972; Hung et al. 1995), suggesting that multiple alphanumeric characters can be recognized in parallel, with no capacity limitation, or at least a capacity that is not taxed by up to the four stimuli typically used. An alternative possibility is that attention for some reason did not select the locations of the presented stimuli during the two intervals of the sequential condition. For example, if attention got “stuck” on the locations of the first half of stimuli, it would fail to show the advantage expected for a limited-capacity process that could devote all its resources to each of the two subsets of the stimuli during their respective presentation intervals.
P. D. L. Howe, Cohen, and Horowitz (2010) adapted this technique to MOT by, in a “sequential” condition, periodically freezing half of the moving targets while the other half continued to move. In the simultaneous condition, all of the targets were periodically frozen. The idea, then, is that any parallel processes will be distributed equally among both moving and any temporarily-stationary targets, whereas a serial process must be reallocated away from the stationary targets during the interval that they are stationary. Such a serial process would then result in higher performance in the condition where targets occasionally pause relative to an “all pause” condition where all targets are temporarily-stationary at the same time.
Across eight experiments, they found that performance was equal or better in the simultaneous condition than in the sequential condition. They interpreted this result as ruling against a serial model whereby tracking is accomplished by switching a process important for tracking from one (or a few) targets to the others. One assumption of this interpretation is that a serial process should be able to efficiently switch away from targets when they are stationary to selectively process the moving targets. As P. D. L. Howe, Cohen, and Horowitz (2010) pointed out, there is good evidence from other MOT experiments that participants can prioritize the most important targets or those perceived to be more difficult to track, for example in virtue of them moving faster (Chen, Howe, and Holcombe 2013; Crowe et al. 2019). A concern with the P. D. L. Howe, Cohen, and Horowitz (2010) experiments, however, is that the longest non-movement (freeze) interval used in the experiments was half a second, and in most of the experiments, the non-movement interval was only a few hundred milliseconds. It is possible that at that rate, a serial process was unable or ineffective at switching from the stationary targets to the moving targets and back again. In addition, the locations of the targets had to be remembered while they were frozen (to distinguish them from the stationary distractors) so that the serial tracking process could switch back to them. These task requirements for non-moving stimuli is quite different from what was involved in traditional applications of the simultaneous-sequential technique (e.g. Shiffrin and Gardner (1972)), where the task was to detect just a single target from among stationary candidate locations.
Regarding the uncertainty around the assumption that a serial process could effectively switch away from the targets when they were stationary during the brief stationary interval, P. D. L. Howe, Cohen, and Horowitz (2010) did conduct one experiment that used a longer, 1.5 s interval, for the movement and non-movement phases. However, this study was deliberately designed to favor serial processing, as a kind of sanity check to establish that the technique worked. They presented only two targets and predictably alternated which of them was moving and which was stationary. In contrast to all of their other experiments they found an advantage for the sequential condition, and they concluded that the 1.5 s interval “was more than sufficient for observers to transfer their attention from one target to another.” But this again raises the question of whether the intervals in the other experiments were simply too short for the serial process to reallocate appropriately. It may be that as one increases the pause interval toward 1.5 s, at some point the sequential condition will show an advantage over the simultaneous condition. What is the criterion for saying what interval is so long that a sequential advantage there no longer speaks to tracking processes? Another issue with this experiment is that because only two targets were used, it likely taps the C≈1 processes more than the previous experiments that used more targets. And, of course, C≈1 processes have a capacity of approximately one, and thus have to process two targets serially.
Returning to the difficult issue of how long of an alternation interval should be used in the simultaneous-sequential design, in a study of word recognition, Scharff, Palmer, and Moore (2011) used the sequential-simultaneous technique to investigate contrast discrimination and visual word recognition. The contrast discrimination task was to judge which of an array of low-contrast discs had a higher contrast than all the rest (which were all identical in contrast), while the word recognition task was to locate the one word, in a display of words, that belonged to a particular category. For example, in one case the target category was “animals,” and the word “dog” (the target) was present in addition to the words ‘car,’ ‘belt,’ and ‘poet.’ Scharff, Palmer, and Moore (2011) found no advantage of the sequential condition for judging which of an array of low-contrast discs had a higher contrast, which they interpreted as consistent with parallel, unlimited-capacity processing. In the word recognition task, in contrast, they found a large sequential advantage, which they took as evidence of serial processing. The alternation interval they used was 1.1 seconds, again raising the possibility that P. D. L. Howe, Cohen, and Horowitz (2010) might have found a different result with longer intervals, as the longest interval used by P. D. L. Howe, Cohen, and Horowitz (2010), save for in the control experiment, was half a second. In sum, while the P. D. L. Howe, Cohen, and Horowitz (2010) evidence might have provided evidence for serial processing and yet did not, a strong possibility remains that in conventional MOT tasks, a serial process rapidly switches among the targets.
8.3 Models of MOT
In the behavioral studies that revealed the temporal limits on tracking, a target and its distractors all shared the same circular trajectory. But in most studies of MOT, the distractors near a target move in many different different directions relative to the target. That is, typical displays have low trajectory among targets and distractors’ trajectories.
All recent models of MOT rely largely on a parallel process for updating of target positions (a serial process is used in some models for other features, which is discussed in ??) (Oksama and Hyönä 2016, 2008; Lovett, Bridewell, and Bello 2019; Li, Oksama, and Hyönä 2019; Srivastava and Vul 2015; Kazanovich and Borisyuk 2006). These parallel theories do not seem able to account for the basic temporal limit discovered with circular trajectories and showcased in 7, nor for the temporal limit’s dramatic decrease with target load. Most model authors do not mention this issue, and it does not appear that their model can explain the phenomenon (Srivastava and Vul 2015; Vul et al. 2010; Ma and Huang 2009). Not only do none of these models predict an increase in temporal interference with target load, most of them never even consider the possibilty of temporal interference.
Two groups of researchers have addressed the temporal interference results. Lovett, Bridewell, and Bello (2019) have a hybrid parallel-serial model of multiple object tracking. Target positions are updated in parallel, but this parallel updating process occurs concurrently with a serial process that, by visiting a target, can utilise the target’s features and compute its motion history. By “motion history,” these researchers seem to mean that the motion direction of the target is processed, which can then be used to predict future positions, which helps disambiguate which is the target and which distractor when objects overlap or come close to overlapping. This helps explain the evidence that localization of targets in such situations can actually be better than targets that are not near distractors (Srivastava and Vul 2016). This serial process can thus explain why predictability of motion trajectories yields an advantage when there are only a few targets, but no detectable advantage when there are more (Piers DL Howe and Holcombe 2012; Luu and Howe 2015).
To explain the temporal resolution and load results of Alex O. Holcombe and Chen (2013), Lovett, Bridewell, and Bello (2019) deploy their model’s serial process in a surprising way. Their idea is that when targets and distractors share circular trajectories as in Alex O. Holcombe and Chen (2013), participants shift from parallel tracking to serial tracking, and this results in the decline in temporal frequency limit with load and also the 2 rps speed limit. But unlike for some of their other claims, they never validate this against data by running the model on these trajectories. Moreover, they don’t explain how the parallel process contributes to performance during the task. The serial process is needed for circular trajectories, they say, to prevent targets from becoming confused with the trailing distractors that soon occupy the targets’ former positions. The model’s serial process allows it to predict future positions and was in fact postulated to address overlap situations. This makes some sense, and the serial process is a natural for explaining the approximately-linear decline in temporal limit with load. But presumably the parallel position updating process is still in operation, as it is in other displays that they say involve serial processing, so why would the pattern of performance (a declining temporal limit) be so determined by the serial process?
For a serial process to determine performance in a model where parallel processing ordinarily plays the dominant role in updating target positions, it seems that the parallel process must somehow be disabled. In other words, in conditions where the serial process determines the performance limit, the parallel process’ updating of positions must be so inferior that it does not substantially contribute to the pattern of performance. Another way of saying this is that the serial process is the performance-limiting process. This type of reasoning based on the pattern of performance thresholds has long been used in psychophysics (e.g., Victor and Conte 2002).
Assuming that the limiting process is indeed serial sampling, we can then infer a characteristic of the parallel updating process. The parallel updating process must be effectively updating targets’ positions more infrequently than about every 180 milliseconds. That is, if it’s true that temporal limit worsens linearly with target load and the serial process determines this performance pattern, implying that the parallel process isn’t contributing much, then the parallel process’s contribution must be worse than that of the serial process. The 3 Hz limit with 3 targets (Alex O. Holcombe and Chen 2013; Roudaia and Faubert 2017), then, places an upper bound on the parallel process’ functioning. It is important, then, to measure the temporal limit with 4 targets. This could further delimit the upper bound on the parallel process. And independent of any particular theoretical reasoning, it would be quite remarkable to see the temporal limit on tracking decrease even further to worse than 3 Hz, indeed to close to 2 Hz if the linear trend continued.
Li, Oksama, and Hyönä (2019) have also addressed the effect of load on the temporal limit. Their latest model, MOMIT 2.0, updates the position of targets with a parallel process. To address the temporal limit, Li, Oksama, and Hyönä (2019) wrote that “when objects move along the same trajectories (e.g., Holcombe & Chen, 2013) and/or are close to each other, high resolution information is required for discriminating the objects. Thus, tracking becomes more serial.” However, the objects in the Holcombe & Chen (2013) studies were not close to each other (they did not intrude on each other’s crowding zones), and I haven’t been able to find anything in the description of MOMIT 2.0 that should be hindered by objects sharing a trajectory. Informally, it doesn’t feel to me that my attention switches to a different mode with circular trajectories, in displays like 7.7. Try it yourself. Of course, it is not necessarily the case that introspection provides any access to parallel versus serial processing.
Given that parallel models can’t account for the decline in temporal limit with load, why have they been fairly successful in mimicking human performance with the typical MOT displays not designed to probe the temporal limit? Well, for typical MOT displays, it remains unclear how much temporal interference we should expect - no one has bothered to calculate the distribution of the intervals between targets and distractors visiting a given location. Second, it is not clear how discriminable the models are from the human data. That is, a number of different models might equally well explain the data. One reason is that potential spatial interference and for temporal interference are confounded in typical MOT displays. That is, trials in which the moving objects come close to each other in space also tend to be trials in which moving objects visit approximately the same location in a short span of time. As a result, a model that embodies spatial interference only may explain the data about as well as one that includes temporal interference.